5 esempi per imparare a programmare in Python
E’ facile imparare a programmare in Python per esempi e stimolare la fantasia circa l’infinità di cose che si possono fare con questo linguaggio; in questo articolo, propongo dei semplici script per creare serie numeriche, costruire dataset in vari formati e registrarli su file, visualizzare grafici, eseguire operazioni in directory e manipolare immagini bitmap.
Python è un linguaggio di programmazione creato nel 1991 da Guido van Rossum con queste caratteristiche:
- essere minimalista, semplice ed intuitivo, ma potente come i linguaggi di programmazione più diffusi;
- liberamente modificabile (open source) per permettere a chiunque di contribuire al suo sviluppo;
- permettere lo sviluppo di codice comprensibile come un testo in inglese;
- veloce da usare, per i compiti di ogni giorno.
Nel corso degli anni, Python ha scalato le classifiche della programmazione, ed è oggi il 4° linguaggio più popolare secondo TIOBE.
L’approccio della programmazione in Python, si basa sull’idea che dovrebbe esistere un solo ovvio modo per fare una certa cosa; questa, si contrappone esplicitamente a quella di Perl, secondo cui c’è sempre un altro modo, per fare una certa cosa.
E’ stato anche coniato il neologismo pythonic (pitonico), per apprezzare un programma che soddisfa le caratteristiche alla base della programmazione in Python.
Inoltre, la PEP#8 e la PEP#257 (Python Enhacement Proposals) concorrono a definire uno stile di codifica consistente in Python, che si può riassumere in questi punti:
- usare 4 “spazi bianchi” (non tabulazioni) per indentare il codice;
- allineare verticalmente il codice all’interno di parentesi in modo consistente;
- limitare le linee a 79 caratteri (usare “" per continuare una istruzione sulla riga seguente);
- mandare a capo gli operatori binari di istruzioni divise su più righe;
- spaziare le definizioni di funzioni e classi con due righe vuote;
- aggiungere righe vuote aggiuntive per suddividere gruppi di funzioni;
- il codice dovrebbe sempre usare caratteri standard UTF-8 (in Python 3) o ASCII (in Python 2);
- le dichiarazioni import dovrebbero essere scritte su righe separate;
- le dichiarazioni import devono essere scritte in cima al file, subito dopo la stringa di intestazione e prima di dichiarare variabili globali e costanti;
- le librerie standard (1) devo essere importate prima di quelle di “terze parti” (2) che precedono quelle “locali” (3);
- istruzioni come “from {module} import *” devono essere evitate;
- le variabili __all__, __author__, __version__ , etc… devono essere inserite subito dopo le istruzioni di importazione delle librerie;
- essere consistenti circa l’uso di virgolette singole (‘) e doppie (“), visto che hanno lo stesso valore!
- usare spazi bianchi con parsimonia ed in modo consistente (vedere esempi nel PEP#8) e gli elementi di liste quando esistono entrambi gli operandi (evitare inutili spazi bianchi);
- scrivere e mantenere aggiornati i commenti di spiegazione del codice;
- un commento deve essere indentato come il codice che precede ed a cui fa riferimento;
- i commenti allineati sulla stessa riga del codice devono essere distanziati da almeno due spazi bianchi;
- non usare mai i caratteri l (elle), O (o maiuscola), I (i maiuscola) per nominare variabili con un solo carattere;
- i nomi dei pacchetti (package) e dei moduli devono essere scritti in minuscolo ed includere “_” se aiuta alla lettura, nel caso di nomi composti da più parole;
- i nomi delle classi sono scritti in maiuscoletto ovvero con la prima lettera di ogni parola in maiuscolo (CapWord);
- i nomi di variabili di tipi (TypeVar) sono scritti in maiuscoletto;
- i nomi di classe delle eccezioni devono terminare con “Error”;
- i nomi di un modulo che possono essere importati con “from {module} import ” devono essere specificati in __all__*;
- i nomi delle funzioni, dei metodi e delle variabili devono essere scritti in minuscolo con eventuali parole separate con “_”;
- i nomi delle funzioni, dei metodi e delle variabili non pubblici devono essere contrassegnati con il prefisso “_” o “__” (se vi è conflitto con un altro nome o si vuole evitare che l’ereditarietà da parte di sottoclassi);
- definire i nomi di costanti con tutte lettere maiuscole;
- gestire le eccezioni specificando classi specifiche;
- includere le “docstring” per supportare la documentazione di un modulo.
Di seguito, cercherò di scrivere script seguendo le linee guida della PEP#8.
In questa pagina pubblico esempi di programmi in Python per imparare il linguaggio ed esaminare alcune tecniche di programmazione. Per facilitare il processo di apprendimento, gli script presentati di seguito hanno una difficoltà via via crescente. Il codice è stato provato sia con Python 2.7 che con Python 3.6: nel caso vi siano differenze, cercherò di esplicitarle proponendo blocchi di codice alternativi.
1) Calcolare l’n-esimo valore della serie di Fibonacci
La serie di Fibonacci è definita matematicamente come:
Per implementare il calcolo di questa funzione in Python, si possono usare almeno 3 metodi:
- il metodo ricorsivo
- il metodo iterativo
- il metodo pitonico
Lo script riportato qui sotto, calcola il valore dell’n-esimo valore della serie di Fibonacci secondo i 3 metodi alternativi; comunque, lo script ha valenza didattica e presenta l’uso di tuple e liste, funzioni, il passaggio di parametri allo script, i costrutti if … elif … else e try … except, l’esecuzione di stringhe come codice con exect e la misura delle prestazioni dello script con la libreria timeit.
#!/usr/bin/env python """ fibonacci.py [method] <n> This script implements functions to calculate the series of Fibonacci numbers with various algorithms. The available methods are "recursive", "iterative" and "pythonic". The default method is "pythonic". The file can be imported as a module or executed as a script. """ import sys import timeit __all__ = [ 'fibonacci_recursive','fibonacci_iterative', 'fibonacci_pythonic','evaluate_arg' ] _METHODS = ('recursive', 'iterative', 'pythonic') _BENCHMARK = False def fibonacci_recursive(n): """Return the Fibonacci serie of number. Implement the recursive method.""" if n == 0: return 0 elif n == 1: return 1 else: return(fibonacci_recursive(n-1) + fibonacci_recursive(n-2)) def fibonacci_iterative(n): """Return the Fibonacci serie of number. Implement the iterative method.""" a, b = 0, 1 for i in range(n): a, b = b, a + b return(a) def fibonacci_pythonic(n, output='fibonacci_n'): """Return the Fibonacci serie of number. Implement the pythonic method.""" serie, i = [0, 1], 2 while i <= n: serie.append(serie[-2] + serie[-1]) i += 1 if (output=='fibonacci_serie'): return serie else: return serie[-1] def evaluate_arg(arg): """Return the argument if it is an integer or the ValueError exception.""" try: n = int(arg) return(n) except ValueError: # stop the script sys.exit('ValueError: the parameter "n" is not an Interger!') def _fibonacci(): """Print the n-th Fibonacci number when the file is executed as a script.""" if len(sys.argv) == 3: method = sys.argv[1] n = evaluate_arg(sys.argv[2]) if method in _METHODS: exec("print(fibonacci_" + method.lower() + "(n))") else: print('The method "' + method + '" is not supported.') elif len(sys.argv) == 2: n = evaluate_arg(sys.argv[1]) print(fibonacci_pythonic(n)) else: print(0) if _BENCHMARK == True and __name__ == '__main__': # execute the file print( # as a script with benchmark timeit.timeit( "_fibonacci()", setup="from __main__ import _fibonacci", number=1 ) ) elif __name__ == '__main__': _fibonacci()
Il benchmark dello script, usando alternativamente i 3 metodi di calcolo della serie di Fibonacci, evidenzia questi risultati:
- il codice della funzione FibonacciRecursive è molto elegante e vicino alla rappresentazione matematica, ma la sua esecuzione è estremamente lenta e non è in grado di calcolare valori elevati della serie a causa del consumo della memoria.
- il codice della funzione FibonacciIterative non è molto fedele alla rappresentazione matematica, ma ha il vantaggio di essere molto veloce ed efficiente.
- il codice della funzione FibonacciPythonic è quello che preferisco in quanto implementa il calcolo della funzione di Fibonacci in maniera abbastanza fedele alla rappresentazione matematica, è veloce ed efficiente, sfrutta il metodo append() delle liste Python e può anche ritornare per intero la serie dei primi “n” numeri di Fibonacci, se la funzione viene chiamata con il parametro output=’fibonacci_serie’.
Lo script fibonacci.py può essere importato come modulo con:
from fibonacci import *
In questo caso, si notino i nomi delle funzioni _evaluate_arg() e _fibonacci(): il simbolo “_” all’inizio di un nome di funzione o variabile, indica all’interprete di escluderli, quando lo script viene importato come descritto sopra. Si ricorda, che è possibile elencare i nomi definiti nel contesto di esecuzione dello script, o in un modulo, con la funzione dir(); per esempio:
dir() dir(fibonacci) dir(__builtin__)
Pe concludere, segnalo che lo script è compatibile sia con Python 2.7 che con Python 3.6, e che quest’ultimo mostra di poter eseguire il codice più velocemente (soprattutto per il calcolo dei primi 10000 valori della serie).
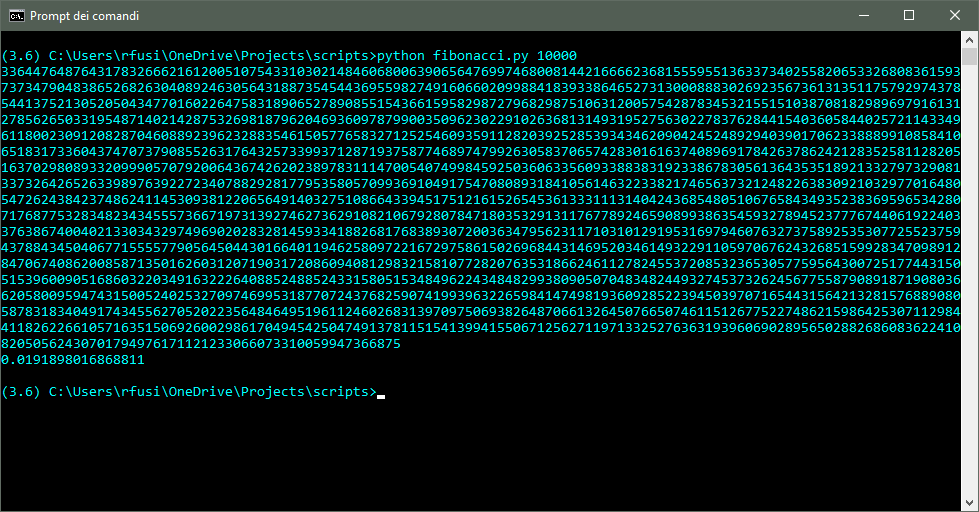
2) Formattare un dataset in una tabella MarkDown, un file CSV, uno stream JSON o un foglio Excel
In questo esempio, richiamerò la funzione fibonacci_pythonic() creata in precedenza per stampare una tabella dei primi n valori della serie, ed il valore della “sezione aurea” (1.618034). Per eseguire lo script, è necessario installare il package openpyxl, che consente di leggere e scrivere file compatibili con Excel 2010 o versioni più recenti.
#!/usr/bin/env python """ fibonacci_dataset.py <n> [format] [device] This script build the serie of Fibonacci numbers till the n-th value and calculate the GoldenRatios. The serie can be presented in various formats: MarkDown, CSV, JSON and Excel. The default format is MarkDown. Finally, the output can be shown on the screen (console) or saved in a file. This script depend from the module "fibonacci.py". Mandatory dependencies: fibonacci.py [format] = md* | csv | json | xlsx [device] = screen* | file * = default """ import sys import traceback import csv import json from openpyxl import Workbook from fibonacci import fibonacci_pythonic as fibonacci, evaluate_arg as evarg FORMATS = ('md','csv','json', 'xlsx') DEVICES = ('screen', 'file') FILENAME = 'fibonacci_dataset' n = None fserie = None dataset = None def format_md(fserie): """Return a MarkDown table with the numbers of Fibonacci and GoldenRatio.""" t = '\n' + 'Serie of Fibonacci, F(i)'.center(43) \ + '\n' + 'with GoldenRatio, F(i)/F(i-1)'.center(43) \ + '\n\n|' + 'i'.rjust(5) + '|' + 'F(i)'.rjust(20) + '|' \ + 'F(i)/F(i-1)'.rjust(15) + '|\n' \ + '|' + '-'*5 + '|' + '-'*20 + '|' + '-'*15 + '|' for i, fibonacci_i in enumerate(fserie): if (i < 2): t += '\n|{0:5s}|{1:20d}|{2:1.13f}|'.format(str(i).zfill(5), fibonacci_i, 0.0) else: t += '\n|{0:5s}|{1:20d}|{2:1.13f}|'.format(str(i).zfill(5), fibonacci_i, float(fibonacci_i)/fserie[i-1]) return(t) def format_csv(fserie): """Return a list of tuples with the numbers of Fibonacci and GoldenRatio.""" s = [('Serie of Fibonacci, F(i) with GoldenRatio, F(i)/F(i-1)', '', ''), ('i', 'F(i)', 'F(i)/F(i-1)')] for i, fibonacci_i in enumerate(fserie): if (i < 2): s.append((i, fibonacci_i, 0.0)) else: s.append((i, fibonacci_i, float(fibonacci_i)/fserie[i-1])) return(s) def format_json(fserie): """Return a JSON dump with the numbers of Fibonacci and GoldenRatio.""" j = [('Serie of Fibonacci, F(i) with GoldenRatio, F(i)/F(i-1)', '', ''), ('i', 'F(i)', 'F(i)/F(i-1)')] for i, fibonacci_i in enumerate(fserie): if (i < 2): j.append((i, fibonacci_i, 0.0)) else: j.append((i, fibonacci_i, float(fibonacci_i)/fserie[i-1])) return(json.dumps(j)) def format_xlsx(fserie): """Return an Excel WorkBook with the nums of Fibonacci and GoldenRatio.""" wb = Workbook() ws = wb.active ws.title = 'Fibonacci' ws['A1'] = 'Serie of Fibonacci with GoldenRatio' ws['A2'] = 'i' ws['B2'] = 'F(i)' ws['C2'] = 'F(i)/F(i-1)' for i, fibonacci_i in enumerate(fserie): if (i < 2): ws.cell(row=i+3, column=1, value=i) ws.cell(row=i+3, column=2, value=fibonacci_i) ws.cell(row=i+3, column=3, value=0.0) else: ws.cell(row=i+3, column=1, value=i) ws.cell(row=i+3, column=2, value=fibonacci_i) ws.cell(row=i+3, column=3, value=float(fibonacci_i)/fserie[i-1]) return(wb) def save_file(dataset, format): """Save the formatted dataset in a file and print a message.""" try: fname = FILENAME + '.' + format if format == 'xlsx': dataset.save(fname) else: f = None if sys.version_info < (3,): f = open(fname, 'wb') else: f = open(fname, 'w', newline='') if format == 'csv': w = csv.writer(f, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL) for r in dataset: w.writerow(r) else: f.write(dataset) f.close() print('Dataset written to the file"{file_name}".'.format( file_name=fname)) except: raise Exception('WriteError', format) try: if len(sys.argv) >= 2: # the script has parameters n = evarg(sys.argv[1]) fserie = fibonacci(n, 'fibonacci_serie') if len(sys.argv) == 2: print(format_md(fserie)) # default execution else: raise Exception('WrongCommand', ' '.join(str(a) for a in sys.argv)) if len(sys.argv) >= 3: # execute with a specified format if sys.argv[2] in FORMATS: dataset = eval('format_' + sys.argv[2] + '(fserie)') if len(sys.argv) == 3: print(dataset) else: raise Exception('WrongFormat', ' or '.join(str(i) for i in FORMATS)) if len(sys.argv) == 4 and dataset != None: # execute with specific device if sys.argv[3] in DEVICES: if sys.argv[3] == 'screen': print(dataset) else: save_file(dataset, sys.argv[2]) else: raise Exception('WrongDevice', ' or '.join(str(i) for i in DEVICES)) except Exception as e: # this is not a phytonic way to handle the exceptions! exc_type, exc_value, exc_traceback = sys.exc_info() if (len(e.args) == 2): type, description = e.args if type == 'WrongCommand': print('The command you have typed is not recognized:' + ' "{command}"'.format(command=description)) elif type == 'WrongFormat': print('The format is not correct; ' + 'try "{formats}"'.format(formats=description)) elif type == 'WrongDevice': print('The device is not correct; ' + 'try "{devices}"'.format(devices=description)) elif type == 'WriteError': print('Error writing the dataset in the' + 'file format "{format}"'.format(format=description)) else: print('Error! Info1="{type}"' + 'Info2="{description}"'.format(type=type, description=description)) else: print('Generic exception!') print('Usage: fibonacci_dataset.py <n> <format> <device>' \ + '\nDetails: ' + str(e) \ + '\nException type: ' + str(exc_type) + '\nExecution value: ' \ + str(exc_value) + '\nExecution traceback: ' \ + str(exc_traceback) + '\nTraceback: ' \ + ''.join(traceback.format_exception( exc_type, exc_value, exc_traceback)) )
Questo script è interessante perché supporta vari metodi per formattare e salvare un dataset; la logica del codice usato nelle varie funzioni di formattazione è del tutto consistente per i vari formati (MarkDown, CSV, JSON ed Excel) e differisce solo per i metodi specifici dei vari moduli utilizzati. Si noti anche che lo script introduce, nella funzione save_file(dataset, format), due alternative per la registrazione dei file di testo con il metodo open(): uno adatto a Python 2 e l’altro per Python 3.
Di seguito, riporto il dataset creato dalla funzione format_md() per i primi 10 valori della serie di Fibonacci.
Serie of Fibonacci, F(i)
with GoldenRatio, F(i)/F(i-1)
| i| F(i)| F(i)/F(i-1)|
|-----|--------------------|---------------|
|00000| 0|0.0000000000000|
|00001| 1|0.0000000000000|
|00002| 1|1.0000000000000|
|00003| 2|2.0000000000000|
|00004| 3|1.5000000000000|
|00005| 5|1.6666666666667|
|00006| 8|1.6000000000000|
|00007| 13|1.6250000000000|
|00008| 21|1.6153846153846|
|00009| 34|1.6190476190476|
|00010| 55|1.6176470588235|
3) Leggere un dataset da file e creare un grafico
Ora, sfrutto gli script creati in precedenza per elaborare delle rappresentazioni grafiche della serie di Fibonacci e delle sezioni auree. Per prima cosa occorre leggere i dati dai file salvati, per poi visualizzarli in un grafico, sfruttando la libreria matplotlib.
#!/usr/bin/env python """ fibonacci_chart.py [format] This script read the dataset of the series of Fibonacci with the GoldenRation, from the file recorded by the script fibonacci_dataset.py and create a chart with 2 vertical axis: one related to the Fibonacci value and the other related to the GoldenRatio. The supported formats are: MarkDown, CSV, JSON and Excel. The default format is MarkDown. [format] = md* | csv | json | xlsx * = default """ import sys import traceback import re import csv import json from openpyxl import load_workbook from matplotlib import pyplot as plt FORMATS = ('md','csv','json','xlsx') FILENAME = 'fibonacci_dataset' def read_md(file): """Return the variables with data from .md file.""" title, x_label, y1_label, y2_label = '', '', '', '' n, fibs, grs = [], [], [] re_header = re.compile( r'\|\s*(?P<hn>.{1,5})\|\s*(?P<hfibb>.{1,20})\|\s*(?P<hgr>.{1,15})\|$' ) re_values = re.compile( r'\|(?P<n>\d{5})\|\s*(?P<fibb>\d+)\|(?P<gr>\d+\.\d+)' ) for i, r in enumerate(file): if i < 4: title += r.strip() elif i == 4: h = re_header.search(r) x_label = h.group('hn') y1_label = h.group('hfibb') y2_label = h.group('hgr') elif i > 5: v = re_values.search(r) n.append(int(v.group('n'))) fibs.append(int(v.group('fibb'))) grs.append(float(v.group('gr'))) return(title, x_label, y1_label, y2_label, n, fibs, grs) def read_csv(file): """Return the variables with data from .csv file.""" title, x_label, y1_label, y2_label = '', '', '', '' n, fibs, grs = [], [], [] dataset = csv.reader(file, delimiter=',', quotechar='|') for i, r in enumerate(dataset): if i == 0: title = r[0] elif i == 1: x_label = r[0] y1_label = r[1] y2_label = r[2] else: n.append(r[0]) fibs.append(r[1]) grs.append(r[2]) return(title, x_label, y1_label, y2_label, n, fibs, grs) def read_json(file): """Return the variables with data from .json file.""" title, x_label, y1_label, y2_label = '', '', '', '' n, fibs, grs = [], [], [] dataset = json.load(file) for i, r in enumerate(dataset): if i == 0: title = r[0] elif i == 1: x_label = r[0] y1_label = r[1] y2_label = r[2] else: n.append(r[0]) fibs.append(r[1]) grs.append(r[2]) return(title, x_label, y1_label, y2_label, n, fibs, grs) def read_xlsx(): """Return the variables with data from .xlsx file.""" title, x_label, y1_label, y2_label = '', '', '', '' n, fibs, grs = [], [], [] wb = load_workbook(FILENAME, read_only=True) ws = wb.active for i, r in enumerate(ws.rows): if i == 0: title = r[0].value elif i == 1: x_label = r[0].value y1_label = r[1].value y2_label = r[2].value else: n.append(r[0].value) fibs.append(r[1].value) grs.append(r[2].value) return(title, x_label, y1_label, y2_label, n, fibs, grs) try: if len(sys.argv) == 2: if sys.argv[1] in FORMATS: FILENAME += '.' + sys.argv[1] if sys.argv[1] == 'xlsx': title, x_label, y1_label, y2_label, n, fibs, grs = eval( 'read_' + sys.argv[1] + '()' ) else: if sys.version_info < (3,): f = open(FILENAME, 'rb') else: f = open(FILENAME, 'r', newline='') title, x_label, y1_label, y2_label, n, fibs, grs = eval( 'read_' + sys.argv[1] + '(f)' ) f.close() fig, p1 = plt.subplots() fig.suptitle(title) p1.plot(n, fibs, 'b-') p1.set_title('...') p1.set_xlabel(x_label) p1.set_ylabel(y1_label, color='b') p1.tick_params('y', colors='b') p2 = p1.twinx() p2.plot(n, grs, 'r-') p2.set_ylabel(y2_label, color='r') p2.tick_params('y', colors='r') fig.tight_layout() plt.show() else: raise Exception('WrongFormat', ' or '.join(str(i) for i in FORMATS)) else: raise Exception('WrongCommand', ' '.join(str(a) for a in sys.argv)) except Exception as e: exc_type, exc_value, exc_traceback = sys.exc_info() if (len(e.args) == 2): type, description = e.args if type == 'WrongCommand': print('The command you have typed is not recognized:' \ + '"{command}"'.format(command=description)) elif type == 'WrongFormat': print('The format is not correct; try ' \ + '"{formats}"'.format(formats=description)) else: print('Error! Info1="{type}" Info2=' + '"{description}"'.format(type=type, description=description)) else: print('Generic exception!') print('Usage: fibonacci_chart.py <format>\nDetails: ' + str(e) + '\nException type: ' + str(exc_type) + '\nExecution value: ' \ + str(exc_value) + '\nExecution traceback: ' \ + str(exc_traceback) + '\nTraceback: ' \ + ''.join(traceback.format_exception( exc_type, exc_value, exc_traceback)) )
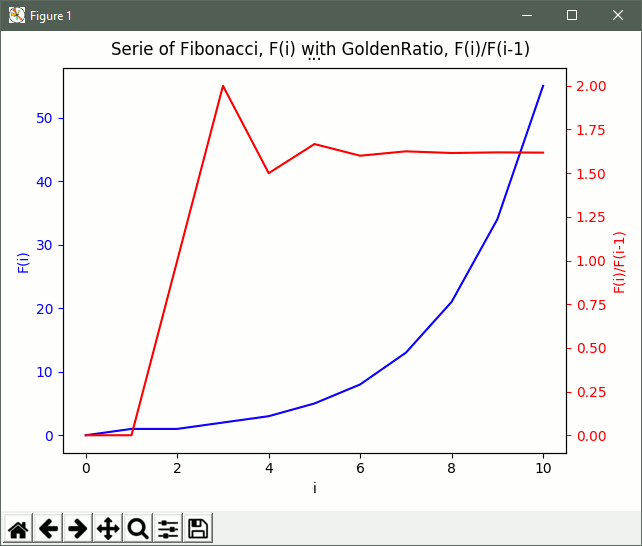
La logica di programmazione usata per leggere i dati dai vari formati di file è consistente e speculare rispetto a quella usata per scrivere i dati, mostrata nel precedente script. Si noti che per estrarre i dati dal file MarkDown, ho impiegato delle Espressioni Regolari ed i metodi search() e group().
Il grafico creato da questo script corrispondente alla serie dei primi 10 valori di Fibonacci e dei relativi GoldeRatio è mostrato di seguito.
4) Gestire file e creare backup compressi nel formato GZIP
Il linguaggio Python si presta a compiere agevolmente anche operazioni di gestione dei files nel proprio sistema. Nel prossimo esempio, creerò uno script che controlla il contenuto della directory corrente, e compie queste operazioni:
- sposta cartelle e files che non sono script nella cartella _various;
- crea una copia di backup degli script Python e li comprime nel formato GZIP (.gz).
Lo script introduce l’uso delle librerie standard gzip, Path e shutil utili per la gestione di files e cartelle.
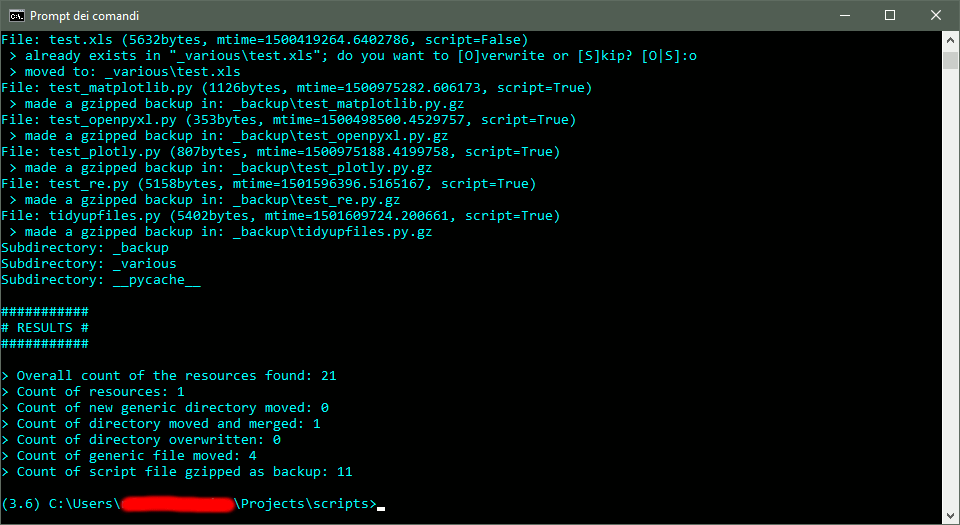
#!/usr/bin/env python """ tidyupfiles.py This script read the contents of the current directory, move the non-python-script files and any subdirectory, to the subdirectory "_various" and create a gzip compressed backup copy of the script files in the "_backup" subdirectory. """ import os import gzip from pathlib import Path from shutil import copyfileobj, copytree, move, rmtree EXCLUDE = ['__pycache__', '_various', '_backup'] # exclusion list w_path = Path('.') # working (current path) b_path = Path(w_path / '_backup') # backup path v_path = Path(w_path / '_various') # various files & dir path n_res = 0 # overall count of the resources found n_skip = 0 # count of resources n_dir_moved = 0 # count of new generic directory moved n_dir_merged = 0 # count of directory moved and merged n_dir_overwritten = 0 # count of directory moved and overwritten n_file_moved = 0 # count of generic file moved n_script_backup = 0 # count of script file gzipped as backup if not v_path.exists(): v_path.mkdir() if not b_path.exists(): b_path.mkdir() print('\nCurrent directory: ' + str(w_path.cwd()) + '\n\nProcessing...') for x_res in w_path.iterdir(): n_res += 1 is_script = x_res.match('*.py*') if is_script: n_path = Path(b_path / str(x_res)) action = None else: n_path = Path(v_path / str(x_res)) action = None if x_res.is_dir(): print('Subdirectory: ' + str(x_res)) if str(x_res) not in EXCLUDE: if n_path.exists(): while action not in ['m','o','s']: action = input(' > ' \ + 'already exists in "' + str(n_path) \ + '"; do you want to [M]erge, [O]verwrite or ' \ + '[S]kip? [M|O|S]:').lower() if action == None: move(x_res, n_path) print(' > moved to: ' + str(n_path)) n_dir_moved += 1 elif action == 'o': rmtree(n_path) move(x_res, n_path) print(' > replaced: ' + str(n_path)) n_dir_overwritten += 1 elif action == 'm': x_items = x_res.glob('**/*.*') for x_item in x_items: x_item_n_path = Path(v_path / str(x_item)) if x_item_n_path.exists(): os.remove(x_item) print(' > item "{x_item}" removed. ' \ + 'Maintained the one in: ' \ + '{x_item_n_path}'.format( \ x_item=str(x_item), \ x_item_n_path=x_item_n_path)) else: move(x_item, x_item_n_path) print(' > item "{x_item}" moved to:' \ + ' {x_item_n_path}'.format( \ x_item=str(x_item), \ x_item_n_path=x_item_n_path)) rmtree(x_res) n_dir_merged += 1 else: n_skip += 1 else: x_res_size = x_res.stat().st_size x_res_mtime = x_res.stat().st_mtime print(('File: ' + str(x_res) + ' (' \ + '{x_res_size}bytes, mtime={x_res_mtime}, ' \ + 'script={script})').format( \ x_res_size = x_res_size, \ x_res_mtime = x_res_mtime, \ script = is_script)) if is_script and str(x_res).endswith('.py'): f_in = open(x_res, 'rb') f_out = gzip.open(str(n_path) + '.gz', 'wb') copyfileobj(f_in, f_out) f_out.close() f_in.close() print(' > made a gzipped backup in: ' + str(n_path) + '.gz') n_script_backup += 1 elif not is_script and (str(x_res) not in EXCLUDE): if n_path.exists(): while action not in ['o','s']: action = input(' > ' \ + 'already exists in "' + str(n_path) \ + '"; do you want to [O]verwrite or [S]kip? ' \ + '[O|S]:').lower() if action == None or action == 'o': move(x_res, n_path) print(' > moved to: ' + str(n_path)) n_file_moved += 1 else: n_skip += 1 print('\n###########' \ + '\n# RESULTS #' \ + '\n###########\n' \ + '\n> Overall count of the resources found: ' + str(n_res) \ + '\n> Count of resources: ' + str(n_skip) \ + '\n> Count of new generic directory moved: ' + str(n_dir_moved) \ + '\n> Count of directory moved and merged: ' + str(n_dir_merged) \ + '\n> Count of directory overwritten: ' + str(n_dir_overwritten) \ + '\n> Count of generic file moved: ' + str(n_file_moved) \ + '\n> Count of script file gzipped as backup: ' + str(n_script_backup))
Dunque, questo semplice script, fornisce esempi in merito al controllo dei file, la creazione, copia e spostamento di directory, ed anche l’acquisizione di input da console in maniera interattiva.
5) Ritagliare, scalare e comprimere immagini bitmap
Il prossimo script introduce la libreria per la manipolazione di immagini bitmap Pillow; si tratta di un componente essenziale e molto potente di Python creato da Alex Clark. In questo script mi limito a mostrare come controllare la dimensioni delle immagini e come modificarne le proporzioni e le dimensioni.
#!/usr/bin/env python """ createcovers.py [ratio] [widths] This script process the images in the current directory, crop them in order to achieve a standard ratio format (for instance, 3:2 or 16:9) and scale them to various widths (for instance: 1170px, 970px, 750px, 620px, 400px, 300px). This script make use of the libray "Pillow". Params: [ratio] = <#_width>:<#_height> [widths] = <#_width1> <#_width2> <#_width3> ... Defaults: ratio = 3:2 widths = 1170 970 750 620 400 300 Required resources: Pillow 4.2.1. (https://pillow.readthedocs.io/en/4.2.x) libjpeg (http://gnuwin32.sourceforge.net/packages/jpeg.htm) """ import glob import os import re import sys import time import traceback from PIL import Image class RatioError(Exception): pass class WidthError(Exception): pass start = time.time() f_exts = ('jpg', 'jpeg', 'gif', 'png') # file extensions of the images w_path = '.\\' # working (current) path p_path = w_path + '_processed\\' # directory for processed files ratio = 1.5 # default target ratio widths = [1170, 970, 750, 620, 400, 300] # default target sizes files = [] # list of the file to process (taken from w_path) images_cropped = 0 # count of the images cropped images_resized = 0 # count of the images produced if not os.path.exists(p_path): os.makedirs(p_path) try: if len(sys.argv) >= 2: for i in list(range(1, len(sys.argv))): if i == 1: reo_ratio = re.match(r'^(\d{1,2}):(\d{1,2})$', sys.argv[i]) if reo_ratio != None: ratio = float(reo_ratio.group(1)) / float(reo_ratio.group(2)) else: raise RatioError(x) elif int(sys.argv[i]) > 0 and int(sys.argv[i]) < 9999: widths.append(int(sys.argv[i])) else: raise WidthError(sys.argv[i]) widths.sort(reverse=True) print('\nCurrent directory: ' + os.path.abspath(w_path) \ + '\nTarget directory: ' + os.path.abspath(p_path) \ + '\nTarget ratio = ' + str(ratio) \ + '\nTarget widths = ' + str(widths) \ + '\n\nPROCESSING...\n') for ext in f_exts: files.extend(glob.glob('*.' + ext)) for file in files: filename, fileext = os.path.splitext(str(file)) img = Image.open(str(file)) img_copy = img.copy() img_width = float(img.size[0]) img_height = float(img.size[1]) img_ratio = img_width/img_height crop = None print(('\nImage: ' + str(file) + ' (' \ + 'img_width={img_width}, img_height={img_height}, ' \ + 'img_ratio={img_ratio})').format( \ img_width = img_width, \ img_height = img_height, \ img_ratio = round(img_ratio, 3)) ) if img_ratio > ratio: # crop horizontally crop = 'horizontally' cut_width = (img_width - (img_height * ratio)) / 2 x1 = cut_width y1 = 0 x2 = img_width-cut_width y2 = img_height elif img_ratio < ratio: # crop vertically crop = 'vertically' cut_height = (img_height - (img_width / ratio)) / 2 x1 = 0 y1 = cut_height x2 = img_width y2 = img_height - cut_height if crop != None: img_copy = img_copy.crop((x1, y1, x2, y2)) print(('> crop image {crop} by ' \ + 'x1={x1}, y1={y1}, x2={x2}, y2={y2};\n' \ + '> new image is {width} width, ' \ + '{height} height, and has a ratio of {ratio}.' \ + '').format(crop=crop,x1=x1,y1=y1,x2=x2,y2=y2, \ width=img_copy.size[0],height=img_copy.size[1], \ ratio=round(img_copy.size[0] / float(img_copy.size[1]), 3))) images_cropped += 1 for w in widths: new_filename = p_path + filename + '-' + str(w) + fileext if fileext in ('.jpg', '.jpeg'): img_resized = img_copy.resize(size=(int(w), int(w/ratio)), \ resample=Image.LANCZOS) img_resized.save(fp=new_filename, dpi=(150,150), \ progressive=True, quality=60, optimize=True, \ subsampling='4:2:2') else: img_resized = img_copy.resize((int(w), int(w/ratio))) img_resized.save(new_filename) print(('> a new image {width}px width has been saved in ' \ + '"{newf}"').format(width=w, newf=new_filename)) images_resized += 1 end = time.time() print('\n###########' \ + '\n# RESULTS #' \ + '\n###########\n' \ + '\n> Overall count of the images found: ' + str(len(files)) \ + '\n> Count of images cropped: ' + str(images_cropped) \ + '\n> Count of images produced: ' + str(images_resized) \ + '\n> Overall execution time: ' + str(round((end - start),1)) + 's') except RatioError as e: print('\nERROR! The specified ratio (' + e.args[0] + ') is wrong!' \ + '\nYou should type a pair of integer of max 2 digits each,' \ + ' written like "##:##".') except WidthError as e: print('\nERROR! The specified width (' + e.args[0] + ') is wrong!' \ + '\nYou should type a positive integer lower than 9999.') except ValueError: print('\nERROR! The specified width is not an integer!' \ + '\nYou should type a positive integer lower than 9999.') except: print('Generic exception!') exc_type, exc_value, exc_traceback = sys.exc_info() print('Usage: createcovers.py [ratio] [widths]\n' \ + '\nException type: ' + str(exc_type) + '\nExecution value: ' \ + str(exc_value) + '\nExecution traceback: ' \ + str(exc_traceback) + '\nTraceback: ' \ + ''.join(traceback.format_exception( exc_type, exc_value, exc_traceback)) )
In definitiva, questo è lo script che uso per creare le immagini di copertina per questo blog. Si noti che lo script introduce nuove tecniche di gestione per file e directory, con le librerie os e glob; inoltre, vengono definiti nuove classi di eccezioni, come estensioni della classe base Exception.

Conclusioni
Pur non essendo un programmatore esperto, ho trovato che Python è un linguaggio veramente molto potente e semplice da usare. Inoltre, in Rete è presente moltissima documentazione grazie alla vasta comunità di sviluppatori che condividono le proprie esperienze e suggerimenti, per risolvere i problemi del processo di programmazione. Ho studiato Python come autodidatta e sono partito dalla documentazione ufficiale disponibile su Python.org.
Riferimenti
- Monthy Python
- Guido von Rossum
- The Python Wiki
- Python
- Python 2.7 documentation
- Python 3.6 documentation
- Dive into Python
- Working with Excel Files in Python
- Popular Python Recipes
- Regular Expression HOWTO
- PEP 8 — Style Guide for Python Code
- Google Python Style Guide
- Invent with python
- Pillow
- Unofficial Windows Binaries for Python Extension Packages
Libri suggeriti
Condividi questo articolo
Se ti è piaciuto questo articolo e pensi possa essere utile anche ad altri, condividilo con i tuoi amici e conoscenti, facendo click sui pulsanti dei tuoi social network preferiti.
P.S. Grazie!
Commenti
Cosa pensi di questo articolo? Hai dei suggerimenti da darmi o vuoi segnalare la tua esperienza in questa pagina? Registrati con Disqus ed inserisci il tuo commento qui sotto!
Inoltre, se lo desideri puoi anche scrivermi una e-mail.